

Autor: Frank Carius
Enterprise Architect / Partner – auf LinkedIn vernetzen
Das Internet ist ohne Router und WAN-Verbindungen nicht vorstellbar. Zusätzlich war schon immer vor allem die Bandbreite beschränkt und eine Überwachung durch ein Netzwerk Monitoring erforderlich. Durch die stärkere Nutzung von Cloud-Diensten, Videokonferenzen und Streaming-Anwendungen haben die Bandbreiten immer weiter zugenommen. Das Monitoring ist in vielen Bereichen jedoch nahezu unverändert beibehalten worden.
Lernen Sie in diesem Blogartikel, warum die reine Bandbreitenmessung nicht mehr ausreicht und wie ein Latenzzeit-Monitoring der Schlüssel zu einer effektiven Netzwerküberwachung ist.
Ursprünge des Netzwerk Monitorings
Im August 1988 wurde mit der RFC 1067 die erste Beschreibung zu SNMP (Simple Network Management Protocol) veröffentlicht, welche die Definition und Grundlage zukünftiger Monitoring Lösungen wurden. Damals entwickelte Tobias Oetiker mit Perl das Programm MRTG (Multi Router Traffic Grapher). Damit konnten bei jedem Aufruf von einem Router die Anzahl der ein– und ausgehenden Pakete und die übertragene Datenmenge in beide Richtungen ausgelesen und geschickt in einer Datenbank gespeichert werden.
Diese generierten Grafiken haben bis heute einen hohen Wiedererkennungswert:

Grenzen der Bandbreitenmessung im Netzwerk
Allerdings müssen diese Zahlen und Grafiken immer interpretiert werden, damit die richtigen Rückschlüsse daraus gezogen werden können. Die maximal nutzbare Bandbreite ist nicht nur durch das Übertragungsmedium vorgegeben, sondern abhängig von der Kapazität der kompletten Verbindung zum jeweiligen Ziel. Daher ist die Aussagekraft der lokalen Auslastung nur eingeschränkt. Die Ermittlung der Bandbreite auf einer Schnittstelle zeigt nur, was auf dieser Teilstrecke übertragen wurde. Die Verbindung zwischen zwei Kommunikationspartnern im Internet besteht allerdings aus sehr vielen Teilstecken, die bei einer reinen Bandbreitenmessung unsichtbar bleiben.
Vergleichen Sie die Problemstellung mit einer Autofahrt. Sie möchten z.B. pünktlich zum Flughafen und schauen dazu durchs Zimmerfenster auf die Straße. Sie stellen fest, dass es weder einen Stau noch sonst eine Überlastung gibt und auch die Garagenausfahrt nicht blockiert ist. Dies entspricht Ihrem Blick auf das Interface Ihrer Firewall. Sie können auf diese Weise nicht erkennen, ob auf dem Weg zum Ziel eine Störung vorliegt. Schon ein Unfall an der nächsten Kreuzung mit einem sich bildenden Stau entgeht Ihren Augen.
Lange Fahrzeiten beim Auto oder lange Paketlaufzeiten im Netzwerk wirken sich aber in anderer Sicht aus. Sie warten nicht mehr, bis die Empfangsbestätigung kommt. Ein TCP/IP-Stack vergrößert die „Windowsize“, d.h. sendet mehr Pakete auf die Reise, um die Daten zu übertragen. Gehen umgekehrt aber Pakete verloren, dann drosseln die Sender die Senderate, da sie von einer Überlastung der Verbindung ausgehen. Dies ist ein vollkommen erwarteter Prozess, denn natürlich muss z.B. ein Server mit einer Gigabit-Karte seinen Versand an die Möglichkeiten der langsamsten Teilstrecke zum jeweiligen Ziel anpassen.
Eine Messung der Bandbreite ist nur dann sinnvoll, wenn Sie den kompletten Verbindungsweg unter Kontrolle haben. Dies war bislang aber auch der Fall, wenn alle Server und Clients On-Premises waren und nur das firmeneigene LAN/WAN zum Einsatz kam. Mit einem vermehrten Cloud Einsatz verändert sich dieses Bild jedoch ständig.
Latenzzeit als Schlüssel für ein effizientes Netzwerk Monitoring
Mit der Cloud und dem Internet empfehlen wir die Laufzeit der Pakete zwischen dem Client und dem Server überwachen. Wenn die Gegenseite z.B. auf einen ICMP-PING oder einen anonymen http-Request antwortet, ist es sehr einfach die Dauer zu messen. Natürlich sind dies zusätzliche Pakete, die etwas Last addieren aber die Aussagekraft macht dies allemal wett. Eine „freie Leitung“ ist genauso wenig mit einer schnellen Leitung gleichzusetzen, wie eine stark belastete Verbindung automatisch eine langsame Leitung bedeutet. So kann eine Autobahn ruhig hoch belastet sein, solange der Verkehr rollt und jeder im Rahmen seiner Zeitvorgabe am Ziel ankommt.
Umgekehrt gilt aber: Wenn die Latenzzeit ansteigt oder für den gewünschten Service zu hoch ist, dann liegt zumindest auf einer Teilstrecke eine Überlastung der vorhandenen Bandbreite vor. Router versuchen immer ein Paket so schnell wie möglich wieder loszuwerden. Überlastungen bauen jedoch eine Warteschlange auf, die sich neben der Latenzzeit auch im Jitter und den Paketverlusten niederschlägt. Diese Werte beeinflussen die Bandbreitenmessung aber werden nicht explizit ausgewiesen.
Passend dazu gibt es Funktionen in Routern, z.B. Cisco IPSL, HP NQA, um als Provider die Teilstrecken kontinuierlich zu vermessen. Als Kunde hilft Ihnen das leider nicht viel, da sich die Provider ungern in die Karten schauen lassen. Jedoch veröffentlichen nur wenige Provider diese Ergebnisse, wie unten am Beispiel von Verizon zu sehen.

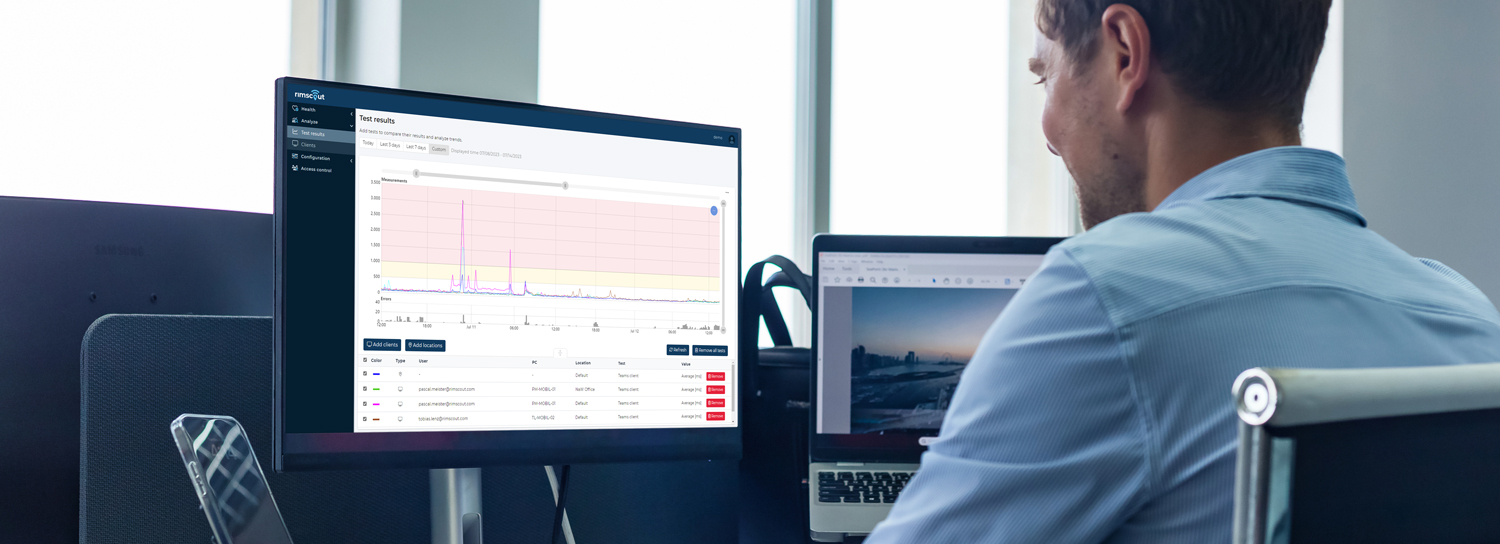
In diesem Beispiel werden Durchschnittswerte an Key-Routern dargestellt. Diese Werte sind so nicht gleich zusetzen mit der eigenen Verbindung. Zusätzlich verschwinden mögliche Peaks im Average. Sie kommen also nicht umhin, eigene Messungen, z.B. mit Rimscout, zu implementieren.
Mehr als nur PING: Vielfältige Wege zur Latenzzeitbestimmung
Der klassische Weg, die Latenzzeit zu messen, erfolgt über ein ICMP-Ping-Paket an die Gegenstelle, welche möglichst schnell darauf antwortet. So kann eine Round-Trip Time (RTT) ermittelt werden, die Auskunft gibt, wie schnell das Paket zu der Gegenstelle und zurück gebraucht hat. Nicht immer ist aber ein PING möglich oder aussagekräftig. Die Gegenstelle, die bei einem ICMP Ping antwortet, ist am Ende ein Server. Man kann über die Antwort also prüfen, wie schnell die Netzwerk-Verbindung zu dem Server ist und ob dieser überhaupt erreichbar ist.
In Cloud-Umgebungen ist HTTPS das dominante Protokoll, über das mit einem Dienst bzw. Service kommuniziert wird. Möchte man also die Erreichbarkeit prüfen, so kann man dies mithilfe einer HTTP Request zu dem Service erreichen und ebenfalls zusätzlich die Round-Trip Zeit messen. Viele Services verlangen eine Benutzer-Authentifizierung, um den Dienst nutzen zu können, jedoch reicht auch eine anonyme Anfrage an die Login-Seite des jeweiligen Cloud-Dienstes aus, um Aussagen über die Netzwerk-Anbindung zu erhalten. Die Antwort beim Aufrufen einer solchen Login-URL liefert zwar nicht unbedingt ein 200 OK zurück, eine Latenzzeitmessung ist aber auch mit anderen Statuscodes kein Problem. Dabei gilt es zu beachten, dass aufgrund der Größe der Pakete, TLS-Handshake, eventuellen HTTP-Proxyservern und Deep-Inspektion die Antwortzeit eines HTTP Requests höher ist als bei einem ICMP Ping. Zusätzlich machen sich Paketverluste meist nur indirekt über eine höhere Latenzzeit bemerkbar, da der darunterliegende TCP-Stack zunächst ein Paket erneut sendet, bevor die Übertragung abgebrochen wird.
Bei Video-Konferenzen wird wiederum bevorzugt UDP als Protokoll für die Übertragung der Sprachdaten verwendet. Hierbei muss natürlich beachtet werden, dass UDP im Gegensatz zu TCP ein verbindungsloses Protokoll ist. Folglich ist das Messen einer Round-Trip Zeit nicht immer möglich, da die Gegenstelle normalerweise nicht antwortet. Jedoch bekommt man besonders bei den TURN-Servern von Microsoft Teams, WebEx, Zoom oder auch anderen Anbietern eine Antwort zurück und kann darüber die Latenzzeit messen.
Kontinuierliche Latenzzeitmessung für präzises Netzwerk Monitoring mit Rimscout
Die steigenden Anforderungen durch z.B. Cloud-Dienste oder Videokonferenzen stellen Ihr herkömmliches Netzwerk Monitoring vor Herausforderungen. Viel wichtiger als eine Überwachung der Bandbreite ist ein Monitoring der Latenzzeit mit den passenden Protokollen je Gegenstelle. Wie beschrieben reicht es hier nicht aus, nur einen Teil anstatt des gesamten Verbindungswegs im Internet zu betrachten, da Überlastungen auf unsichtbaren Teilstrecken verborgen sein können. Dafür sollten die Latenzen immer end-to-end, also aus der Sicht der Anwender, gemessen werden.
Die Herausforderung besteht jetzt darin, direkt von mehreren oder allen Clients die Gegenstellen zuverlässig zu messen. Viele Cloud-Dienste erfassen als Teil der Telemetrie schon solche Informationen aber stellen Ihnen diese nicht oder nur eingeschränkt als Kunde bereit. Zudem enthalten diese Daten Lücken, wenn die Software nicht genutzt wird oder auf dem Client nicht zum Einsatz kommt. Die Vergleichbarkeit unterschiedlicher Clients, Standorte und Netzwerkanbindungen ist daher nur sehr schwer möglich.
Wir empfehlen eine kontinuierliche Messung der relevanten definierten Verbindungen und Gegenstellen durch möglichst viele Clients mit Rimscout. Mit von uns vordefinierten und von Ihnen selbst konfigurierten Prüfungen erhalten Sie von allen Clients kontinuierliche Latenzzeitmessungen. Durch geeignete Grenzwerte erkennen Sie so problemlos alle problematischen Clients, Standorte oder Internet-Provider. So kreisen Sie über gezielte Vergleiche zwischen den verschiedenen Messungen die Ursache immer genauer ein und der Weg zur passenden Lösung verkürzt sich zunehmend.